NDMP Backup in 2026: The Protocol Isn’t the Problem. Your Management Layer Is.
There’s a narrative floating around that NDMP is dead. That it’s a legacy protocol clinging to relevance while modern API-based approaches have moved on. Right? And I get the appeal of that story. It’s clean. It’s simple. But if you’re actually running a large NAS estate in production, you know it’s not that straightforward.
NDMP backup still protects the majority of enterprise NAS data. Not because people haven’t heard of the alternatives, but because ripping out a backup protocol that’s wired into your filer infrastructure is a project nobody wants to fund when the current approach works. The real pain, for most teams we talk to, isn’t the protocol itself. It’s everything around it: the legacy GUIs, the CLI-only configuration, the two-console shuffle just to troubleshoot a single failed job.
So the question worth asking isn’t “NDMP or not?” It’s: does your NAS backup problem actually require a protocol change, or does it need an operational upgrade?
NDMP Is Still the Default for a Reason
NDMP was purpose-built for NAS. It moves data directly from filer to backup target without routing through a media server, which keeps backup traffic off your production LAN. For NetApp ONTAP, Dell PowerScale (Isilon), and other enterprise filers, the NDMP integration is mature and well-tested. The storage vendors themselves support and maintain it.
We’ve been working with NDMP for over 25 years at Catalogic. We’ve seen the cycles: from on-prem to cloud, then back to on-prem for some workloads, from tape to disk to object storage. Through all of that, NDMP has remained the most widely supported protocol for NAS data protection. NetBackup, Commvault, IBM Storage Protect, HPE Data Protector, Arcserve: they all rely on it as their primary mechanism for backing up filers. Commvault’s documentation, updated as recently as January 2026, still treats NDMP as a first-class citizen.
Organizations running 50 TB to multi-petabyte NAS environments don’t switch protocols on a whim. The filer-side services are proven. The backup catalogs are built. The recovery runbooks are written. That’s a lot of operational capital.
The Real Limitations (and the Ones That Get Exaggerated)
Now, NDMP does have genuine weaknesses that matter more today than they did ten years ago. Let’s be specific about what those are.
Throughput on High-File-Count Volumes
NDMP was designed around single-stream backups per volume. For a 500 GB volume, that’s fine. For a 20 TB volume packed with millions of small files, it becomes a bottleneck. The NAS spends most of the backup window scanning metadata rather than transmitting data. Community reports from NetApp and Dell consistently describe throughput dropping to 10 MB/s in these scenarios. At that rate, backing up 10 TB can stretch into weeks.
Some implementations support parallel streams (up to eight in certain configurations), but parallelism within NDMP is implementation-specific and often limited by the filer’s own service capacity.
The Incremental Cycle
Traditional NDMP implementations use a level 0 through level 9 cycle, which means a full backup after every nine incrementals. Without a reliable changed-file-tracking mechanism at the filer level, the backup application has no efficient way to identify what changed. That forces periodic full rescans. On large volumes, that means periodic multi-day backup windows.
No Standard Data Format
NDMP doesn’t specify a data format for backup streams. Data backed up from a NetApp filer can’t necessarily be restored to a Dell PowerScale. If your DR strategy assumes cross-platform recovery, this is a real constraint.
These are legitimate limitations. But here’s what’s important: they don’t hit every environment equally. If your volumes are in the single-digit terabyte range, your file counts aren’t in the tens of millions, and your recovery targets are same-platform, NDMP performs just fine. The protocol isn’t the bottleneck. Something else is.
What Actually Hurts Day to Day
Here’s what gets lost in the protocol debate. For most organizations, the daily pain of NAS backup has nothing to do with how data moves off the filer. It’s everything around it.
Think about what managing NDMP backups actually looks like in many environments. A Java-based console that hasn’t been meaningfully updated in over a decade, pinned to a specific JRE version that conflicts with everything else on the admin workstation. CLI-only configuration for anything beyond basic job setup, which means tribal knowledge locked in the heads of two or three senior people. Separate tools for backup management versus storage management, so troubleshooting a single failed job means switching between consoles and correlating timestamps manually. Monitoring that amounts to parsing email alerts or scraping log files because the backup software doesn’t expose metrics through any modern interface.
This overhead is real and measurable. And it’s often more expensive in engineer-hours than any throughput limitation. A backup job that completes reliably and can be configured, monitored, and troubleshot from a single browser-based interface by any member of the ops team is a better outcome than a theoretically faster job that only two people in the organization know how to manage.
A Decision Framework: Protocol Change or Operational Upgrade?
Not every NAS backup problem requires a protocol migration. Here’s a practical way to evaluate which camp you’re in.
You probably need a different approach to data movement if your NAS volumes routinely exceed 10 TB with tens of millions of files and backup windows are consistently blown; your DR plan requires cross-platform restore (NetApp to PowerScale, or to cloud-native storage); or you’re already running modern filer firmware with vendor API support and can take advantage of snapshot-based change tracking.
You probably need an operational upgrade if NDMP throughput is adequate for your volumes and SLAs but managing jobs is painful; your team spends more time fighting the console than fixing actual backup failures; you’re running filer platforms where NDMP is the best-supported integration; or you want unified backup management across NAS, VMs, databases, and cloud workloads without migrating your entire infrastructure.
For teams in the second camp (and that’s most of the enterprises we work with), the priority should be finding a management layer that wraps NDMP with something modern while keeping the protocol doing what it does well.
What Modernizing NDMP Backup Actually Looks Like
This is where I want to get specific, because “modernization” is one of those words that means everything and nothing.
Replace the legacy console with a browser-based interface and a REST API. DPX ships with an HTML5 web application alongside the legacy desktop client, and exposes full management capability through a REST API. The web interface requires no JRE, no installer, just a browser. It covers job management, scheduling, node configuration, tape library management, and reporting, including RPO compliance and unprotected-node detection. The REST API gives operations and automation teams programmatic access to the same functions, making DPX scriptable and integration-ready without screen scraping or proprietary tooling. The combined result: any ops team member can manage NAS backup jobs from a browser, and any automation pipeline can do the same without a human in the loop.
Consolidate NAS backup alongside everything else. One of the most common complaints we hear is tool sprawl: one console for NAS, another for VMware, another for physical servers, maybe a fourth for cloud. DPX manages NDMP backup for NetApp and Isilon alongside Hyper-V, VMware, physical file servers, and S3 workloads from a single dashboard. That’s not a convenience feature. It’s the difference between an ops team that can cross-train and one where NAS backup is a single point of knowledge failure.
Keep file-level restore working. This matters more than people think. NDMP dump-style backups in DPX maintain a full file catalog, so recovery means searching for and restoring individual files or folders. Not restoring an entire volume and fishing through it. Not telling the requester “we’ll need to do a full volume restore, it’ll take 48 hours.” That file-level granularity is often the reason NDMP is still preferred over snapshot-only approaches for operational recovery scenarios.
Support the filers you actually have. DPX supports generic NDMP (which covers a wide range of vendor devices) plus NetApp-specific extensions like CAB (Cluster Aware Backup) and SMTape. Whether you’re on ONTAP 7-mode, clustered Data ONTAP, or PowerScale, the integration works with the filer firmware you’re running today. Not just the latest release.
Make the economics work. This is a practical concern that doesn’t get enough attention in technical blog posts. If you’re protecting 20 TB of NAS data, the licensing cost of your backup software shouldn’t require a board-level conversation. DPX is licensed to make NDMP backup economically viable as a standalone use case, not just as an add-on to a six-figure enterprise agreement.
When NDMP Really Isn’t Enough
I want to be direct about this: there are environments where NDMP is the wrong answer. If you’re dealing with volumes in the hundreds of terabytes with file counts in the hundreds of millions, and your backup windows are measured in weeks instead of hours, the single-stream architecture of NDMP will hold you back regardless of how good the management layer is. API-based approaches that use vendor-native change tracking and parallel data reads are genuinely better for those workloads.
Similarly, if cross-platform restore is a hard requirement (say, recovering NetApp data onto cloud-native storage as part of a DR scenario), NDMP’s lack of a standard data format is a blocking issue, not an inconvenience.
The point isn’t that NDMP is always the right choice. It’s that for a large segment of enterprise NAS environments, the protocol is fine and the management experience is what needs fixing.
Key Takeaways
- NDMP remains the most widely supported NAS backup protocol in enterprise environments. The “NDMP is dead” narrative is vendor marketing, not operational reality.
- The protocol’s real limitations (throughput on high-file-count volumes, periodic full backups, no standard data format) matter at extreme scale, but don’t affect every environment equally. Be honest about whether they affect yours.
- Most NAS backup pain comes from operational friction: legacy consoles, CLI dependency, tool sprawl, poor observability. An operational upgrade often delivers more value than a protocol migration.
- Modernizing NDMP means a browser-based UI, consolidated multi-workload management, file-level restore with a searchable catalog, broad filer support, and economics that make sense for NAS-focused deployments.
- Before starting a protocol migration project, ask whether the problem is actually how data moves off the filer, or how your team manages and monitors that process day to day.


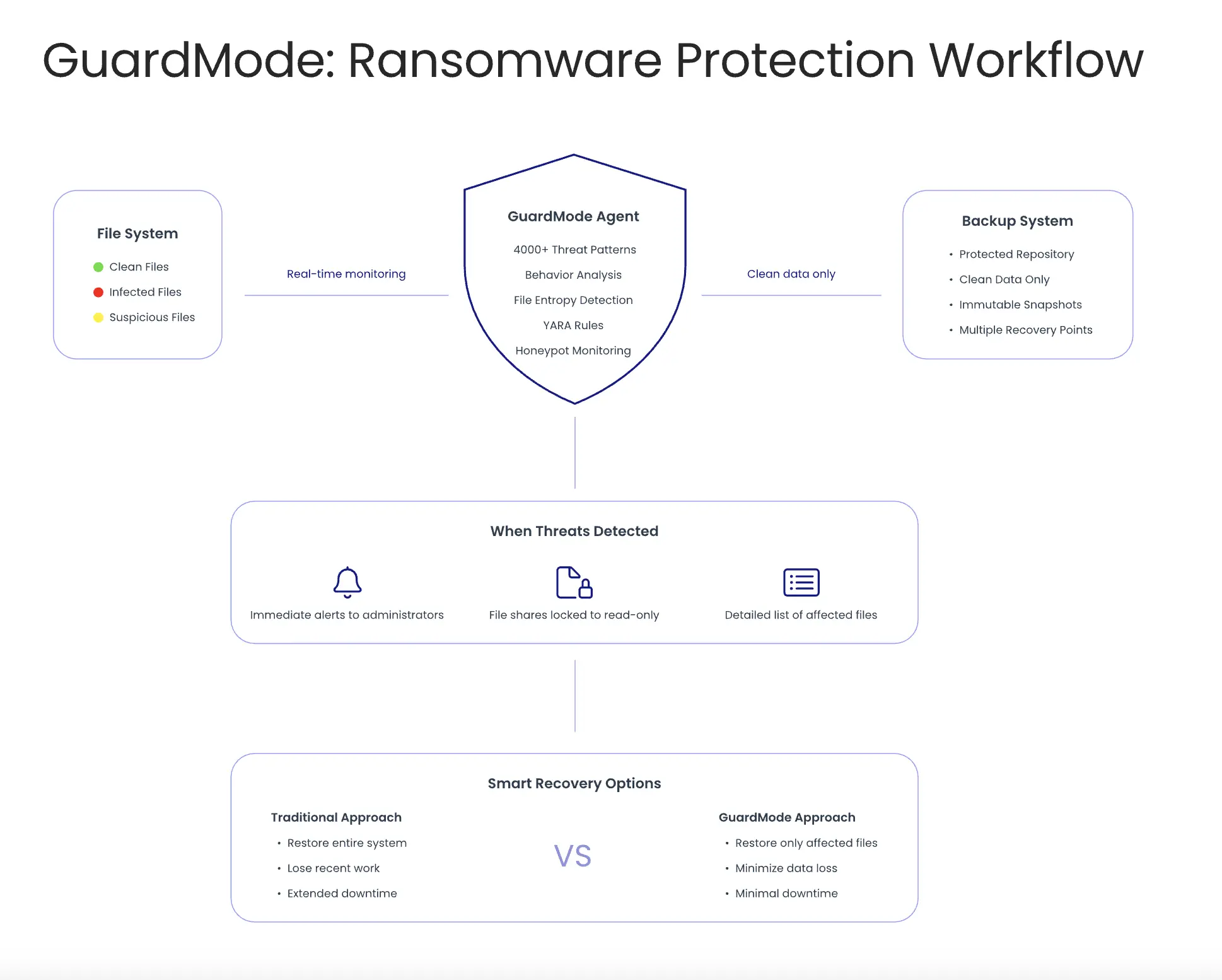
 The recovery process generally follows these steps:
The recovery process generally follows these steps: Limitations and Challenges
Limitations and Challenges